

Attention mechanisms are a crucial foundation for the success of large language models. However, as the context window size increases, the computational power required to compute the attention matrix grows exponentially. When the context window size reaches 1000K, storing the attention matrix alone requires approximately 2TB of GPU memory, which will eventually lead to insufficient processing power for large models.
To address this problem, DeepSeek envisioned using contextual optical compression to compress text tokens using visual tokens. The DeepSeek-OCR paper ultimately validated the feasibility of this idea and inspired the industry to try to make large models forget things like humans.
Optical Computing System Solution Provider Lightstandard stated that the verification of the feasibility of contextual optical compression further illustrates that optical computing will become the future of large language models, and the company is actively promoting the integration of optical computing with large models.
01
Compress text using "visual tokens"
In the DeepSeek-OCR paper, DeepSeek demonstrated the method's ability to compress visual images using data. Even when the compression ratio reaches 10 times, it can still maintain 96.5% accuracy. This amazing performance reveals the feasibility of visual compression.
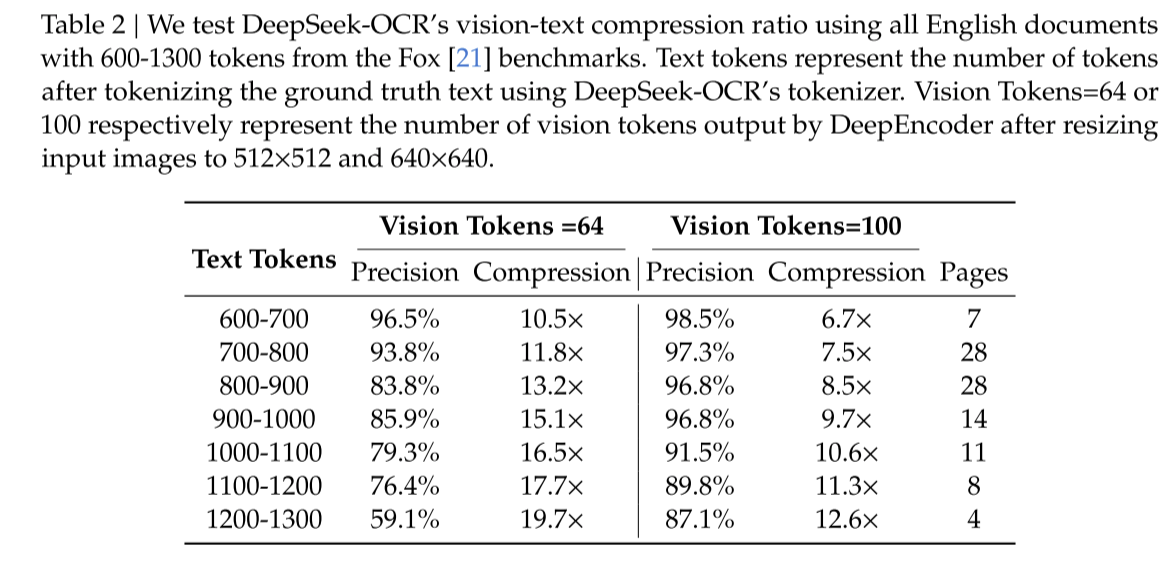
(DeepSeek-OCR paper data)
DeepSeek's DeepEncoder module is the core engine for contextual optical compression, comprising three modules: SAM, two convolutional blocks, and CLIP. The SAM module first segments the original image into multiple local windows using a window attention mechanism. Then, using the ViT image recognition model, it calculates the correlation between the images in each local window through a matrix. Regions with high correlation are fused together to unify their association, while blank regions, due to poor correlation, retain low feature values and are discarded by the convolutional blocks in the next step, achieving both information extraction and compression. Finally, the extracted and compressed visual tokens are input into CLIP, which uses a global attention mechanism to capture the overall semantics and context of the image from this compressed information. At this point, DeepSeek-OCR completes all compression steps, successfully compressing data that originally required 1000 text tokens into 100 visual tokens.
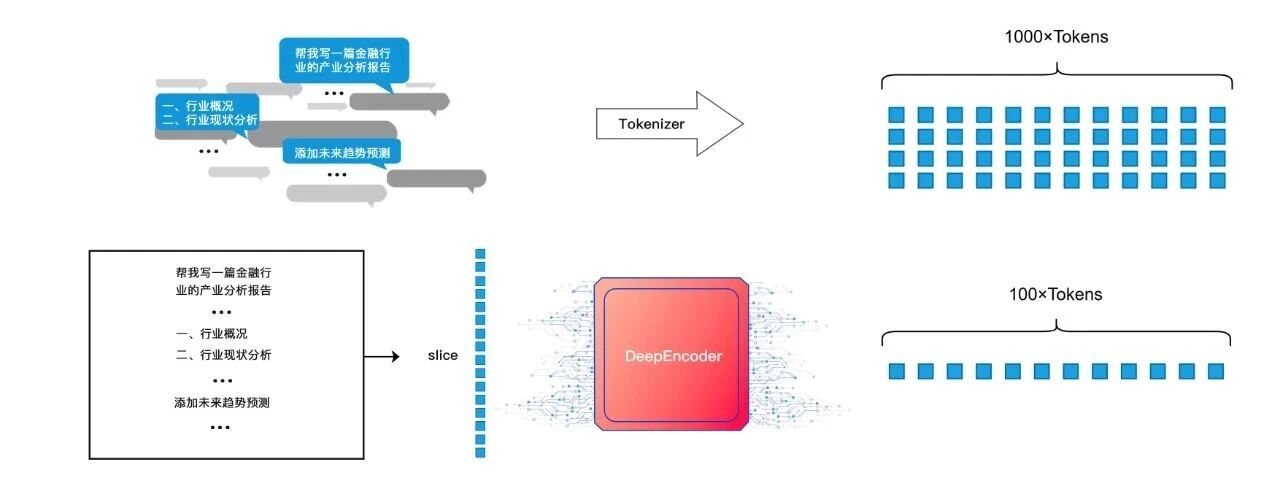
(DeepSeek-OCR compression diagram)
02
Why optical computing is better suited for context compression
From the process perspective, DeepSeek-OCR mainly uses two major structures to achieve optical compression: the ViT image recognition model and CNN convolutional operations. The key steps are introducing an attention mechanism in ViT and using different convolutional kernels in CNN to filter information.
Essentially, both the attention mechanism in ViT and the filtering of different convolutional kernels in CNN are computational processes of information aggregation. This means that both ViT and CNN require an efficient hardware platform for computation.
Information compression mechanisms like ViT and CNN, which involve vector-matrix multiplication and convolution at the underlying computational level, are naturally well-suited for parallel computing architectures using optical computing. This allows optical computing chips to achieve information compression at a much faster speed and with significantly lower energy consumption compared to electrical chips. Furthermore, flexibility is greatly increased; the propagation paths and computational logic within optical computing chips can be adjusted to meet different needs.
As shown in the figure below, by introducing computation into the optical domain, DeepEncoder, after being accelerated by the fully programmable in-memory optical computing engine with a matrix scale of 128×128 independently developed by Lightstandard, can achieve a 100-fold increase in computational efficiency and a 10-fold increase in energy efficiency for this type of computing task.
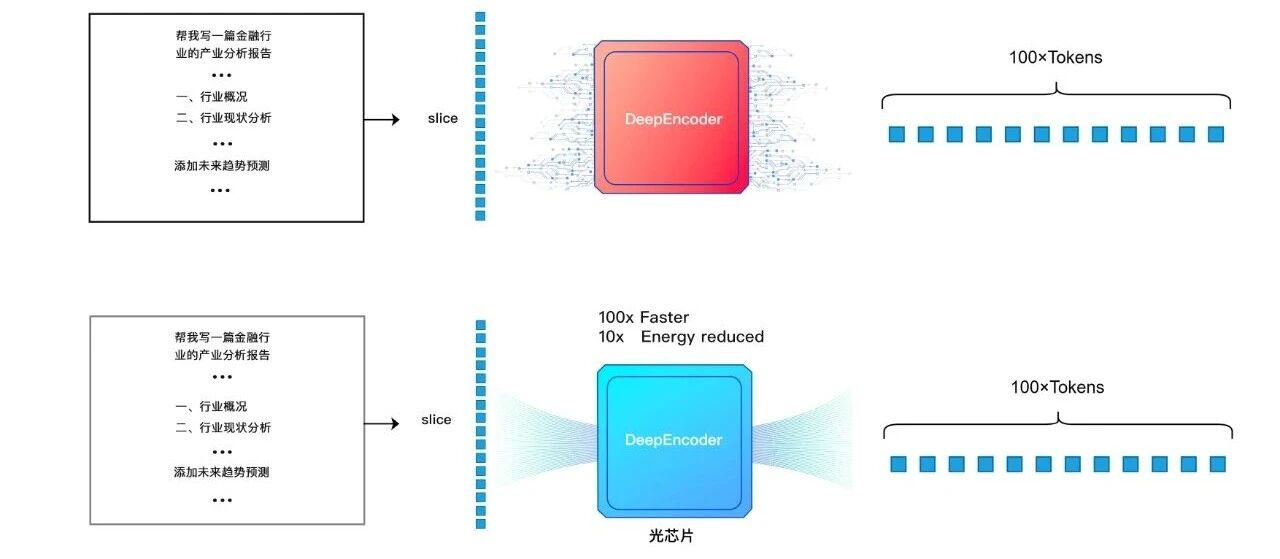
(Diagram of DeepSeek-OCR optical computing acceleration)
Why can optical computing achieve highly efficient acceleration and extreme energy efficiency in information compression? Through testing, Lightstandard believes that optical computing has an overwhelming advantage over GPUs in brain-like tasks such as compressing context.
The most obvious advantage is the simplification of the computation process. In traditional electronic chips, multiple computational processes such as convolution, scaling, pooling, activation, attenuation, and sampling quantization need to be completed. However, in optical computing, image information can be naturally calculated and processed through optical means. The above-mentioned computational processes can be completed during propagation, without relying on any additional power consumption.
As shown in the figure below, image information is directly input into the optical computing chip through light refraction, transmitting light signals of different frequencies. After modulation and coupling on different computing optical paths, compression is achieved, enabling computation without additional energy consumption. Furthermore, the unique in-memory computing architecture of Lightstandard allows its optical computing engine to maintain "zero static sustaining power" when processing batch tasks.
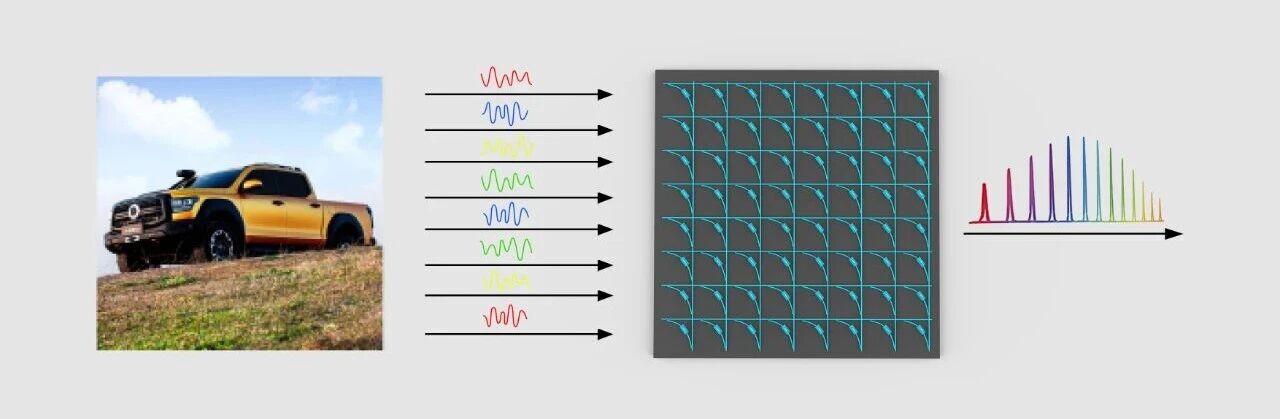
(Illustrative diagram of image information input)
Another major advantage of optical computing chips is their scalability. Whether it's increasing array size to enhance parallelism or increasing parameter refresh rates to improve dynamic programmability, both are achievable, with higher limits and lower power consumption than electronic chips. Arbitrary dimensional expansion provides a vast space for long text reasoning that goes beyond traditional electrical computing paths.
In addition to images, Lightstandard is attempting to encode other forms of information into optical signals of different frequencies and input them into optical computing chips. Through modulation and coupling on different optical paths, it can also achieve computing without additional energy consumption.
(Illustrative diagram of other forms of information input)
03
A Grand Model for Future Connectivity in Optical Computing Hardware
Following the release of DeepSeek-OCR, DeepSeek proposed exploring algorithms based on the human brain's forgetting mechanism, the core of which is to use fuzziness to replace past deletion. Lightstandard believes that the core of forgetting algorithm mechanisms remains efficient feature extraction, reducing feature dimensionality, and even fusing with existing features to form new features.
Therefore, the company envisions using a special optical path structure and even heterogeneous integration design to leverage the non-volatility of phase change materials (PCM) to efficiently simulate human brain neurons associated with information, thereby achieving efficient computing and brain-like information encoding and storage.
The emergence of DeepSeek-OCR provides a new approach to the generalized design of optical computing chips and may become a breakthrough point for connecting optical computing hardware with large models.
Lightstandard plans to leverage the advantages of optical computing chips to launch dedicated hardware for context compression, dedicated hardware for AI tasks, and a supporting software stack, enabling integration with large-scale models. This will not only achieve a nearly 100-fold increase in computing power and a more than 10-fold increase in energy efficiency on existing models, but also provide a highly efficient computing foundation for future new computing paradigms.
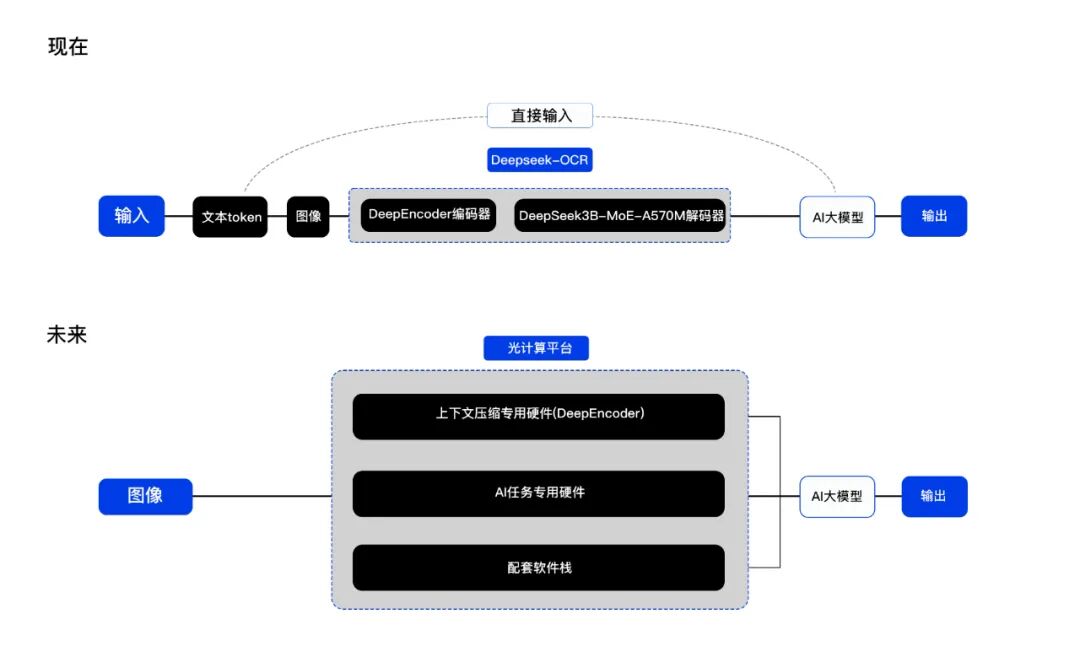
(Schematic diagram before and after the fusion of the optical computing platform and DeepSeek-OCR)
Today, with the widespread use of large models, long text inference presents new challenges to parameter scale, bandwidth, and context information compression capabilities. Traditional GPUs are limited by memory walls and power density, often constrained by video memory and bandwidth when expanding context. Therefore, optical computing is needed to leverage its advantages of high computing power, high bandwidth, and low power consumption to change the current situation of large models.
Lightstandard stated that it will gradually build a next-generation disruptive platform system for large-scale all-optical AI computing, providing full-stack optical computing solutions covering all scenarios.
Recommended News
Recommended News
Recommended News



